Introducing Generative AI in Blender
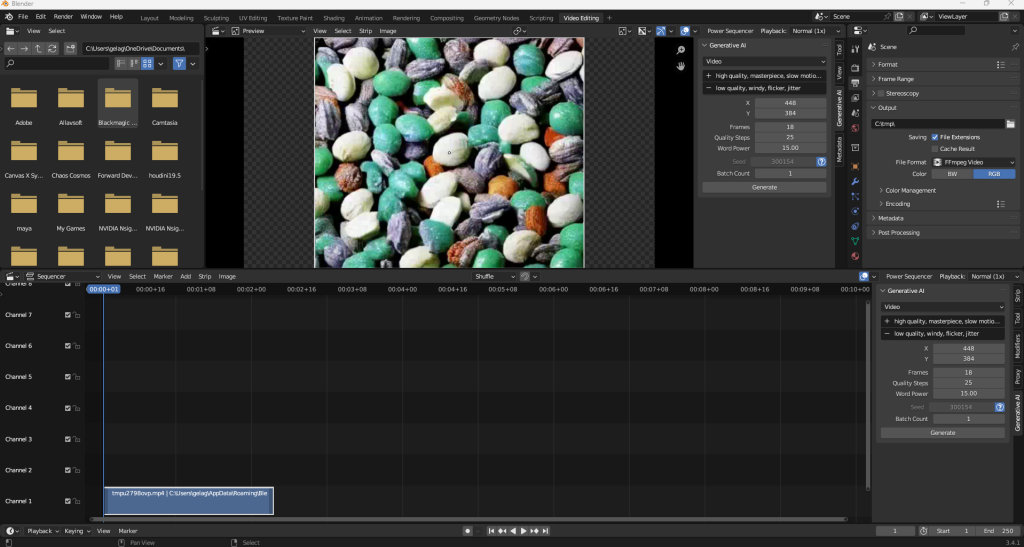
Blender, a powerful software widely used in the field of 3D animation and visual effects, now offers a range of generative AI capabilities. By leveraging AI models such as Modelscope, Animov, Stable Diffusion, Deep Floyd IF, AudioLMD, and Bark, users can seamlessly convert text prompts into engaging videos, mesmerizing images, and immersive audio experiences.
Generative AI has revolutionized the field of digital content creation by allowing the transformation of text prompts or strips into stunning videos, captivating images, and immersive audio experiences. In this article, we will delve into the exciting capabilities of generative AI within the Blender software. With features like text-to-video, text-to-audio, and text-to-image conversion, users can unleash their creativity and bring their ideas to life effortlessly. Let’s explore the functionalities, requirements, installation process, and available models to unlock the full potential of generative AI in Blender.
Features of Generative AI in Blender
Text-to-Video: Generate captivating videos by simply inputting text prompts or strips. Users can specify parameters such as seed, quality steps, frames, and word power to tailor the generated video according to their vision.
Text-to-Audio: Transform text into high-quality audio, opening up avenues for creating music, speech, or sound effects. Models like AudioLMD and Bark provide diverse options for generating audio content based on different prompts and expressions.
Text-to-Image: Convert textual descriptions into visually stunning images. Utilizing AI models like Stable Diffusion and Deep Floyd IF, users can generate images that align with their creative concepts and preferences.
Seamless Workflow and User-Friendly Interface
The Blender add-on for generative AI offers a streamlined workflow for users to generate content efficiently. With batch operation capabilities, multiple text strips can be processed in one go, enabling users to create a series of videos, audio tracks, or images effortlessly. The user-defined file path allows for convenient organization and easy access to the generated files.
Installation and Setup
To get started with generative AI in Blender, follow these simple steps:
Install Git for your platform, ensuring it is added to the system’s PATH.
Download the generative AI add-on from the provided link.
You can use git clone https://github.com/tin2tin/Generative_AI.git or download zip file from github or from my server Generative_AI-main.zip
Run Blender as an administrator (for Windows users) to avoid permission errors.
Install the add-on through Blender’s Preferences panel.
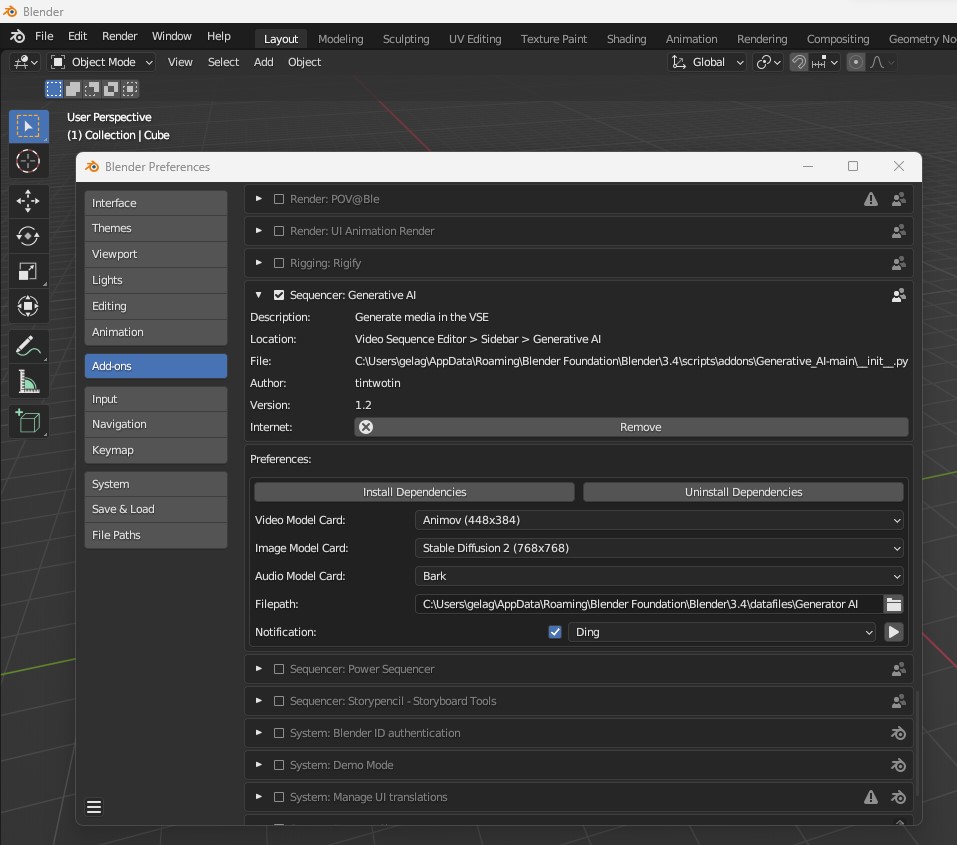
Access the add-on’s user interface in the Sequencer sidebar, under Generative AI.
Install all dependencies by clicking the respective button in the add-on preferences.
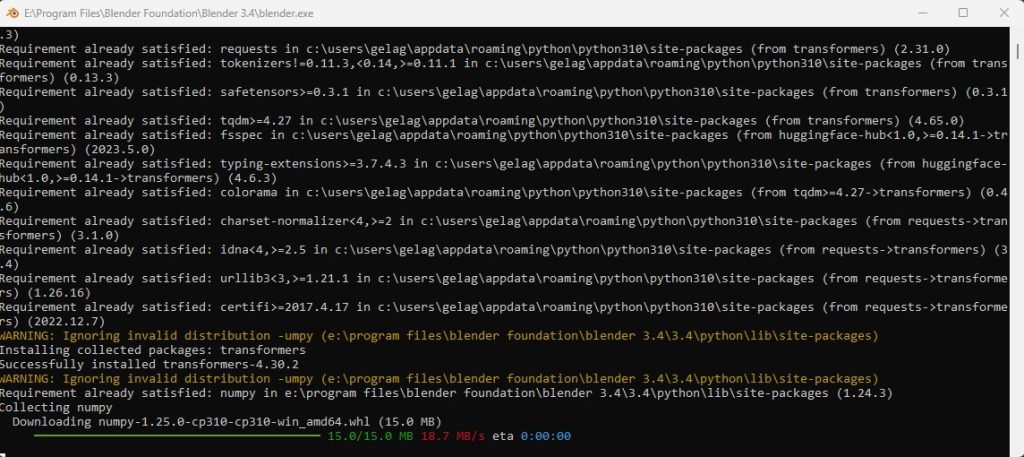
Wait for the installation to complete, which may require downloading several gigabytes of data. Grab a cup of coffee during this time.
Restart Blender if prompted to do so.
Set the desired model cards for different modes (video, image, audio) in the add-on preferences.
Enhancing the Experience with Model Cards
Model cards offer a selection of pre-trained AI models to further enhance the generative AI experience in Blender. The Modelscope, Animov, Stable Diffusion, Deep Floyd IF, AudioLMD, and Bark models provide a diverse range of capabilities and creative possibilities. Users can leverage prompt suggestions available online or refer to the respective model documentation for optimal usage and desired outcomes.
Optimizing Text-to-Audio Conversion
When utilizing the AudioLDM model, experimenting with different prompts can yield impressive audio results. Try prompts like “Bagpipes playing a funeral dirge,” “Punk rock band playing a hardcore song,” “Techno DJ playing deep bass house music,” or “Acid house loop with jazz.” Additionally, incorporating specific notations like [laughter], [music], [gasps], or capitalization for emphasis can add depth and nuance to the generated audio. The Bark model, on the other hand, provides a wide range of predefined notations and speaker libraries to tailor the generated audio according to specific requirements.
Find Bark documentation here: https://github.com/suno-ai/bark
Unleashing Creativity with Text-to-Video/Image Conversion
By harnessing models such as Modelscope, Animov, Stable Diffusion, and Deep Floyd IF, Blender empowers users to create captivating videos and visually stunning images. While the Modelscope model may have a watermark due to its Shutterstock training, it remains a valuable resource for non-commercial purposes. Including relevant keywords or prompts like “anime” when using the Animov model can optimize the output, especially with the Animov-512x model. Users can explore online resources for prompt suggestions specific to the Stable Diffusion models, further expanding the creative potential of their projects.
Fine-tuning and Customization Options
Blender’s generative AI add-on allows users to adjust various parameters to achieve the desired results. The seed, quality steps, frames, and word power options provide flexibility and control over the generated content. Experimenting with different combinations can lead to unique and intriguing outcomes, tailored to individual creative visions.
Uninstalling and Managing Models
In case users wish to uninstall specific models or clear cache directories, they can locate the Hugging Face diffusers models in the designated cache directory. On Linux and macOS systems, the cache directory is typically found at ~/.cache/huggingface/transformers, while on Windows, it is located at %userprofile%.cachehuggingfacetransformers. Deleting individual models from these directories allows users to manage their installed models effectively.
Modules
Diffusers: https://github.com/huggingface/diffusers
ModelScope: https://modelscope.cn/models/damo/text-to-video-synthesis/summary
Animov: https://huggingface.co/vdo/animov-0.1.1
Potat1: https://huggingface.co/camenduru/potat1
Zeroscope: https://huggingface.co/cerspense/zeroscope_v1_320s
Polyware’s T2V: https://huggingface.co/polyware-ai/text-to-video-ms-stable-v1
AudioLDM: https://huggingface.co/cvssp/audioldm-s-full-v2 https://github.com/haoheliu/AudioLDM
Bark: https://github.com/suno-ai/bark
Deep Floyd IF: https://github.com/deep-floyd/IF
For more or less comfortable work, you will need a video card with at least 12 GB of video memory or of course Nvidia 24 Gb VRAM videocard. I tested the work even on my video card with 6 GB of video memory. But video generation takes a very long time, 18 frames approximately 3 hours or more! I provide as evidence the result of a video generated using my 6 GB video card.
Please subscribe to my Facebook page and Telegram channel for more information and discussion of related issues.
I will be glad to see everyone on the new Facebook page